Web crawling is a brilliant source to bootstrap your application. Almost every application requires data of some sort and why not just pick up some public data available on the world wide web!
In this introduction I'll cover the core ideas behind web-crawling and web-crawling with python.
What's Web Crawling?
First it's important to wrap your head around the stages of web crawling program.
crawler or spider A program that connects to web pages and downloads their contents.
To put it simply it's a program that goes online and finds two things:
- data the user is looking for.
- more targets to crawl
e.g.
- Go to http://shop.com
- Find product pages
- Find and download product data such as price, title, description
Stages
A usual web-crawler program will be made from 4 core stages:
- Discovery - find product urls to crawl
- Consumer - consume product urls and retrieve their htmls
- Parser - parse html data into something useful
- Processor - process the data with pipeline, filters etc.
- Loop!
note: these stages don't have to have to happen in strict order
There can be few more steps in between but the core logic of a web crawler looks like this:
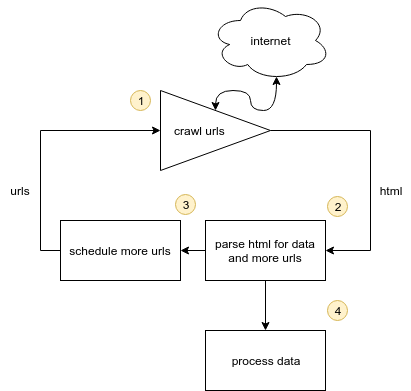
worth noting that websites can return all sorts of content not only html. Some return json, some just text and some code like javascript.
In very simplest python pseudo code for a crawler would look like this:
url = 'https://www.python.org/jobs/'
job_urls = find_job_urls(url)
data = consume(job_urls)
data = process(data)
import json
with open('output.json','w') as f:
f.write(json.dumps(data))
You can find full crawler at the end of blog post.
Crawling
There are two ways to crawl http urls:
- Synchronous - slow and simple
- Asynchronous - complex but blazing fast.
Which one to use? As beginner or if you don't need speed stick with synchronous approach. The programming is much more simple and easier to debug. However asynchronous knowledge is very valuable and learning it is a great idea
Synchronous
This is very straight-forward approach. Everything goes in your program's order:
for every url: download page -> parse it -> store it -> repeat
For synchronous crawling most popular library is requests
However while this approach is simple and easy to maintain it ends up being very slow as every time program connects to a webpage to download data program need to wait for it to response - in the mean time program could be doing something else: like download another webpage, parse the data or store it.
when is synchronous approach good enough? Often a lot of applications don't need to retrieve a lot of data (e.g. football match score crawler) then sync code is more than enough.
Alternatively a lot of website have request limits that are high enough that match synchronous code slowness.
Asynchronous
Async programming is a bit more complex to wrap your head around but to put it shortly it allows the code to be executed in pararel.
Your program can schedule 100 request to a website at once and handle response as they come in or do something else!

So it terms of speed it vastly outperforms synchronous crawlers as they don't have to wait!
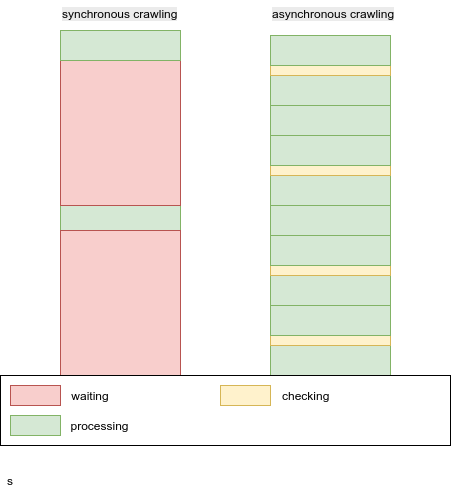
"checking" square here is very simplified representation of async mechanism
For asynchronous crawling there are a lot of choices and no clear defacto standards. I recommend requests-futures for caroutine based approach and twisted or treq for callback based approach.
caroutines or callbacks? While caroutines are much more favored async principle these days callbacks have a special place in web-crawling community as the logic tends to match scraping patterns better
Parsing
There are all sorts of data types on the web, but most likely you're either will be crawling html or json.
Html
Html is a subset of xml tree structures. It's a great data type for representing structure, however it's not a great data type for representing data itself.
<html>
<body>
<div id=name> rubber chicken </div>
<div id=price> 55.99 </div>
</body>
</html>
So usually this data is either converted to database tables or json, csv documents:
-
csv documents:
name,price rubber chicken, 55.99 -
json documents:
[ { "name": "rubber chicken", "price": 55.99 } ] -
database tables
------------------------------ | name | price | ------------------------------ | rubber chicken | 55.99 |
What data type to chose for output? Anything works! However some data types are easier to work than others.
jsonis an easy to format to work with as it translates to pythondictseamlessly.csvis great to work with as it's an easy format to write and parse.json-linesformat is best of both worlds. What about data bases? Document based databases are often preferred when web-scraping. Like MongoDB and couchDB, they are great for storing json data, while relation databases are a bit less straight-forward but come with their own benefits (like sqlite and mariadb)
Parsing html
Since html is a structural data type we can parse it quite easily. For that there are xpath and css selectors and appropriate python libraries that implement this selector logic.
For python all you need is parsel which allows you to use both types of selectors to parse data. Alternatively you can also use a popular alternative beautifulsoup4
Here's a parsel example:
from parsel import Selector
html = """
<html>
<body>
<div id=name> rubber chicken </div>
<div id=price> 55.99 </div>
</body>
</html>
"""
selector = Selector(text=html)
# css selector
name = selector.css('#name::text').extract_first()
# xpath selector
price = selector.xpath('//div[@id="price"]/text()').extract_first()
print(price, name)
# ' 55.99 ',' rubber chicken '
Surprisingly simple!
Which one, css or xpath? Generally css selectors are much easier and more bautiful but xpath selectors are much powerful. So ideally use css and fallback to xpath when encountering something more complicated.
Parsing with regex? Generally parsing html with regex is a bad idea as regex patterns will quickly become unreliable. Html is structure data type - embrace it!
Json
This type of data is often used by website internally together with javascript. Sometimes you can crawl these pages directly either through public or internal websites API.
It's super convenient as you don't need to do any parsing yourself!
Parsing json
Parsing json is super easy as it can be read as python dictionary right out of the box:
import json
json_data = '{"data": [{"name": "product", "price": 55.99}]}'
data = json.loads(json_data)
print(data['data']['price'])
# 55.99
These days more and more web pages become dependant on javascript thus often providing json data
Synchronous Example
Lets write a simple article crawler for python blog posts!
for this we'll use parsel and requests packages. You can get them via pip:
pip install parsel requests
Our spider logic would follow:
- Go to page with all links to blog posts
- Go to every blog post
- Extract data
- Store data to file
import json
from urllib.parse import urljoin, unquote
from parsel import Selector
import requests
session = requests.session() # 1
def discover():
"""Discover job urls in jobs listing page"""
jobs_url = 'https://www.python.org/jobs/'
jobs_html = session.get(jobs_url).text
jobs_sel = Selector(text=jobs_html)
urls = jobs_sel.css('.listing-company-name a::attr(href)').extract()
return [urljoin(jobs_url, url) for url in urls]
def parse(url, html):
"""Parse job html"""
sel = Selector(text=html)
company = sel.css('.listing-location a::text').extract_first()
email = sel.css('.reference.external::attr(href)').extract_first()
title = sel.xpath("//h2[contains(text(),'Job Title')]"
"/following-sibling::text()").extract_first('')
description = sel.xpath("//h2[contains(text(),'Job Title')]"
"/following-sibling::p/text()").extract_first('').strip()
return {
'url': url,
'location': company,
'title': title.strip(),
'description': description,
'email': unquote(email.split(':')[-1]),
}
def process(data):
"""Here usually you'd add extra processing steps
like upload to database
or adding crawl time
or determening whether to drop results based on their values"""
return data
def consume(urls):
"""Consume job urls by downloading them, parsing data and saving to disk"""
for url in urls:
print(f'crawling job: {url}')
html = session.get(url).text
yield process(parse(url, html))
def crawl():
"""
Complete crawl loop:
1. Discover job listing urls
2. parse html for data
3. process data
4. store data
"""
urls = discover()
data = consume(urls)
with open('collected.json', 'w') as f:
f.write(json.dumps(list(data), indent=2))
if __name__ == '__main__':
crawl()
As you can see the crawler is split into 4 parts:
- Discovery - discover job urls in listing page
- Consumer - crawl job urls
- Parser - parse data from job htmls
- Processor - process data and save it to file
1 - connection sessions establish connection to server and keeps it open for more requests, this speeds up crawling and puts less stress on the host.
Conclusion
Data is often the core of application functionality and web-crawling is a great tool to easily take advantage of public data available online.
Crawling is a diverse, multi-step process with a lot of viable approaches but to start off sticking with syncrhonious requests and html parsers like parsel can be more than enough for most projects.
For further reading it's important to take a look at web caching and rate limiting, proxies and failure and memory managing. Finally there's a whole other problem of scaling both crawling and data storage when it comes to millions of results.
I'll be covering these in later blogs